Transformer
Transformer
Word Embedding
每一个单词都可以表示成n维向量的形式,这样我们就可以用计算机来处理文本了。因此通俗来说,word embedding就是一个把输入文本转化成词向量矩阵的一个操作。
假设我们有一个句子:”I love machine learning”,经过tokenizer处理后,得到4个token,分别是”I”、”love”、”machine”、”learning”。然后我们就可以利用word embedding把四个token转化成四个词向量拼接而成的矩阵。假设每个token的词向量维度是512,那么经过word embedding后,我们会得到一个512x4的矩阵X
在预处理的时候,我们会通过学习得到一个vocabulary embedding的矩阵作为词表,然后利用
得到最终的word embedding矩阵X. 这个矩阵操作就相当于在vocabulary embedding里面寻找input token的位置,然后提取出来再拼接成矩阵X.(在上面的例子中,就是找I,love,machine,learning四个词在vocabulary embedding中的位置,然后提取出来再拼接成矩阵X) 其中 是vocabulary embedding, T是token indices, 每列只有input token在vocabulary embedding的位置处才是1,其余都是0. 用来从vocabulary embedding里提取input里每一个token的词向量。
下图展示了这一过程,其中D是词向量维度,N是input的token数,V是词表大小.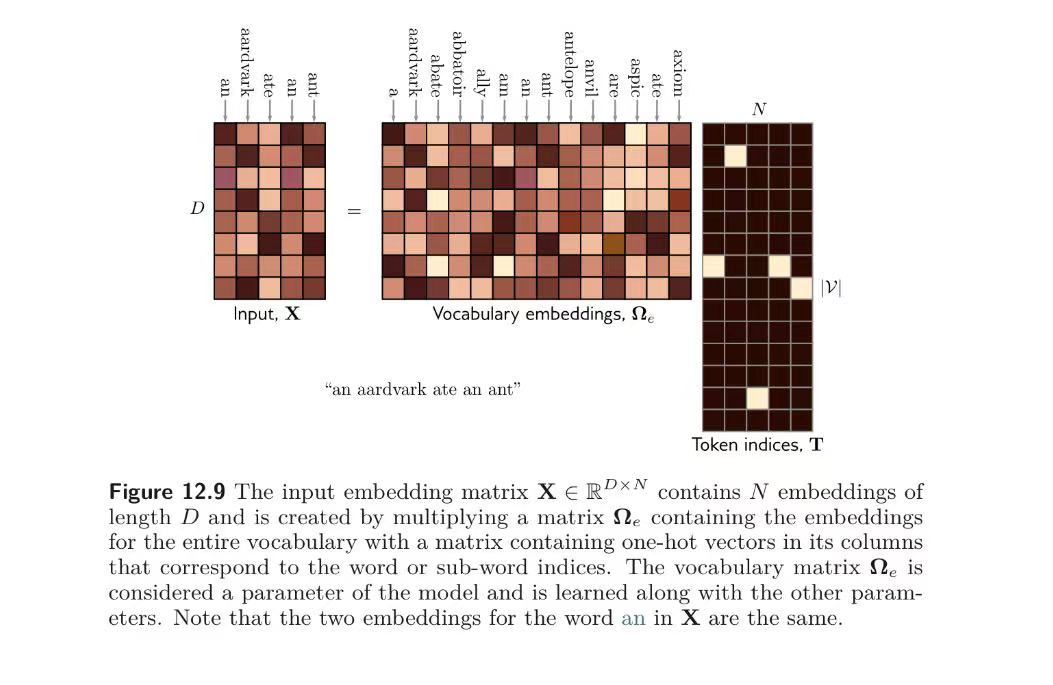
在BERT中,我们采用上下文词嵌入(contexual embedding), 即每个token的词向量不是简单的从vocabulary embedding中提取,而是根据上下文来学习得到的。
Positional encoding
为什么需要positional encoding?
在文本中,显然相同token在不同位置的含义是不同的,举个例子
“我爱学习”
“学习爱我”
在这两个句子中,”我”,这个 token 所处位置不同,含义也是不同的。
但self-attention 不知道序列中每个 token 的位置信息,模型会把上面两个句子当作一样的。所以这个时候需要 positional encoding 来给模型提供位置信息。
具体操作是,给每个 token 一个唯一的位置编码,然后把位置编码加到 token 的 embedding 上。
其中 X 是所有 token 的 embedding 矩阵,Ω 是位置编码矩阵。
那么怎么获得这个位置编码矩阵 Ω 呢? 可以通过直接添加一个预设好的位置编码矩阵,或者通过学习得到一个位置编码矩阵。
上面说的这个方法是传统的 positional encoding 方法,称为absolute positional encoding。它的缺点是只能表示绝对位置,即只能表示“这个词在句子中是第 5 位”,不能表示“这个词与另一个词相距 5 个 token”。
所以,我们可以使用 Relative Positional Encoding的方法做位置编码,核心思想是让模型学习 token i 和 token j 之间的相对距离(j – i)对注意力的影响,而不是 token 的绝对位置。
也就是说 attention 不只是 Q * K,还加入一个项: position i 到 position j 的相对位置 embedding。
以下是三种主流relative positional encoding 的公式
Transformer-XL 类型
在 attention score 中显式加入 R_(i-j)
传统 attention:
加入相对位置后:
其中:
R_(i-j):表示 token i 到 token j 的相对距离的 embedding
u, v:全局可学习偏置
i - j:token 之间距离
T5 的 Relative Position Bias
T5 方法更简洁,只添加一个可学习的相对位置偏置项,不修改 Key / Query:
RoPE:Rotary Positional Embedding(GPT/LLaMA 主流使用)
将 token 的 embedding 做一个角度旋转:
特点: 自然包含相对位置关系+非常适合长序列扩展
NoPE: No Positional Embedding
我们在attention里的casual mask中已经隐式地引入了position信息,所以可以直接不加任何的位置编码
in genral不如前面的几个methods,不过也不错
Scaled dot product attention
这是transformer的核心,总的来说就是这个公式
注意,上面这个公式是把输入X当作n*d的矩阵来算的公式。由于本blog借用了prince书的图集,因此我们这里遵循prince书里的标记,使用的是d*n的输入X(相当于做了个转置),所以公式应该是
那么Q,K,V是怎么来的呢? 首先,在经过word embedding 和 positional encoding 之后我们有一个输入矩阵X,大小是d*n, 代表了n个d维的token.
然后我们通过三个线性变换得到Q,K,V矩阵:
其中 是可学习的权重矩阵,大小都是 . 是bias,大小都是d*1的向量,1是1*n的全1向量.
我们可以将大矩阵拆解成单个向量来看,将X拆成n个d维向量,每个向量代表一个token.
那么Q,K,V也可以拆成n个d维向量,分别是 .
那么上面的线性变换可以写成:
观察上式容易知道bias对于每个向量而言是不变的,一共三个bias,所有q向量共用一份,所有k向量共用一份,所有v向量共用一份,因此要乘.
拆成向量之后,attention计算可以写作:
是 与 之间的attention,代表了 对 的注意力程度。计算公式为: 就是在求这q和k这两个向量的点积. 这个点积算出来就是第j个token对第i个token的attention程度。如下图所示: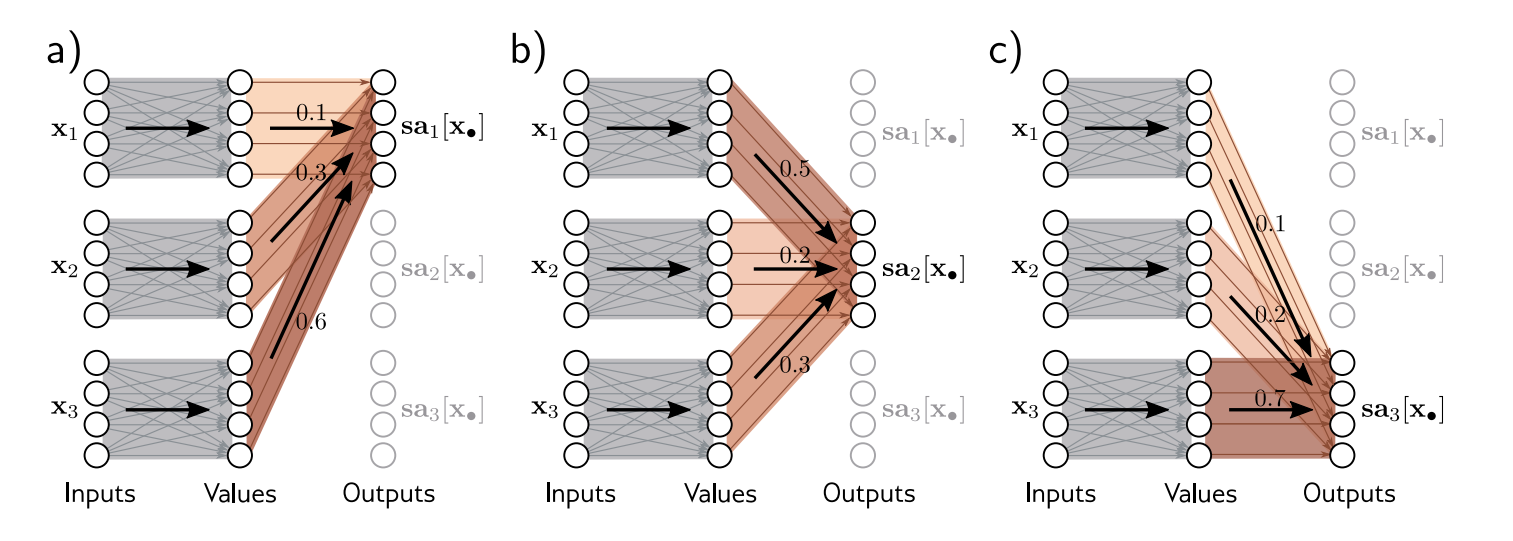
x先经过线性变换得到v,然后对于不同位置的sa,拿对应的q向量去和所有token的k做点积(这也是为什么这玩意叫dot product attention),然后softmax一下得出概率,再用概率去乘v相加,得出一个加权和。最终这些所有的sa向量合在一起就是attention矩阵了。对应上文中的
写成矩阵形式就是. 下图展现了矩阵形式下的attention计算过程:
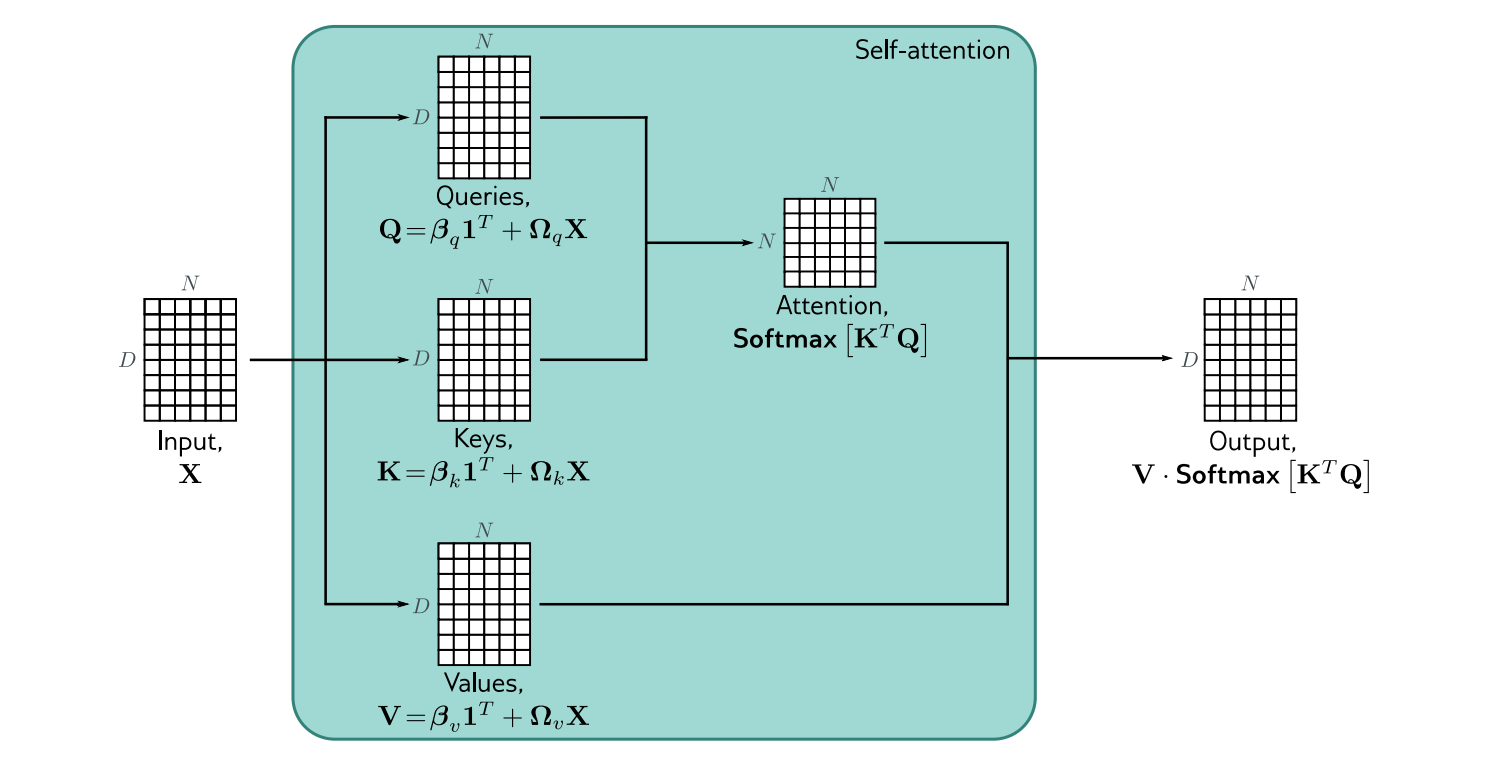
可以看出,上面的图和公式里就差一个根号dk了,那么为什么要在softmax里面除以一个根号dk呢?
为什么要scale
我们把除以一个根号dk的操作称为scale。 因此现在这个scaled dot product attention的名字就很好理解了。那么为什么要scale呢?
在计算 的时候,假设Q和K的元素是独立同分布的随机变量,均值为0,方差为1。那么点积的结果的方差就是d(向量维度)。当d很大时,点积的结果的方差很大,会出现数组中一个很大,另一个很小的情况,在softmax之后一个概率趋近于1,一个概率趋近于0。这样会导致softmax函数的梯度矩阵的一些元素变得非常小,出现梯度消失的问题,从而使得模型训练变得困难。
为了解决这个问题,我们对点积结果进行缩放,除以 ,这样可以使得点积的结果的方差保持在一个较小的范围内,从而避免梯度消失的问题。
softmax名字的由来
这里扯一句题外话,softmax为什么叫softmax? 首先我们要知道,其实还有一个东西叫hardmax。 对于 这个数组,如果我们求hardmax,那么就是 , 只取最大的那个,剩下的完全不考虑。 而softmax则是根据权重算出一个概率, 求得, 然后并不是粗暴地取最大的那个,而是根据这个概率分布来取,最大的数被取到的概率最大,但也有一定概率会取到其他的数。
casual masking
计算attention矩阵时,需要加一个casual mask,防止模型能够看到后面的词。这样模型在预测的时候只能看自己的前文,防止“作弊”
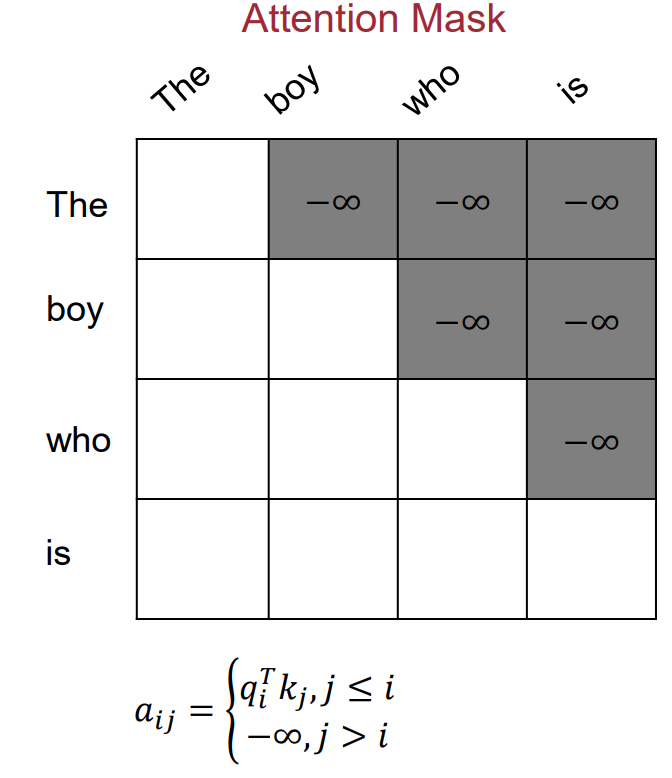
注意这里加的都是负无穷,因为我们要过softmax.
Multi-head Attention
Q,K,V 都是 d*n (n个d维的token) 的矩阵,将 d*n切分为h个(d/h)*n 的矩阵做 h次atteention计算,再将结果合并,这就是多头注意力机制。
如下图所示:
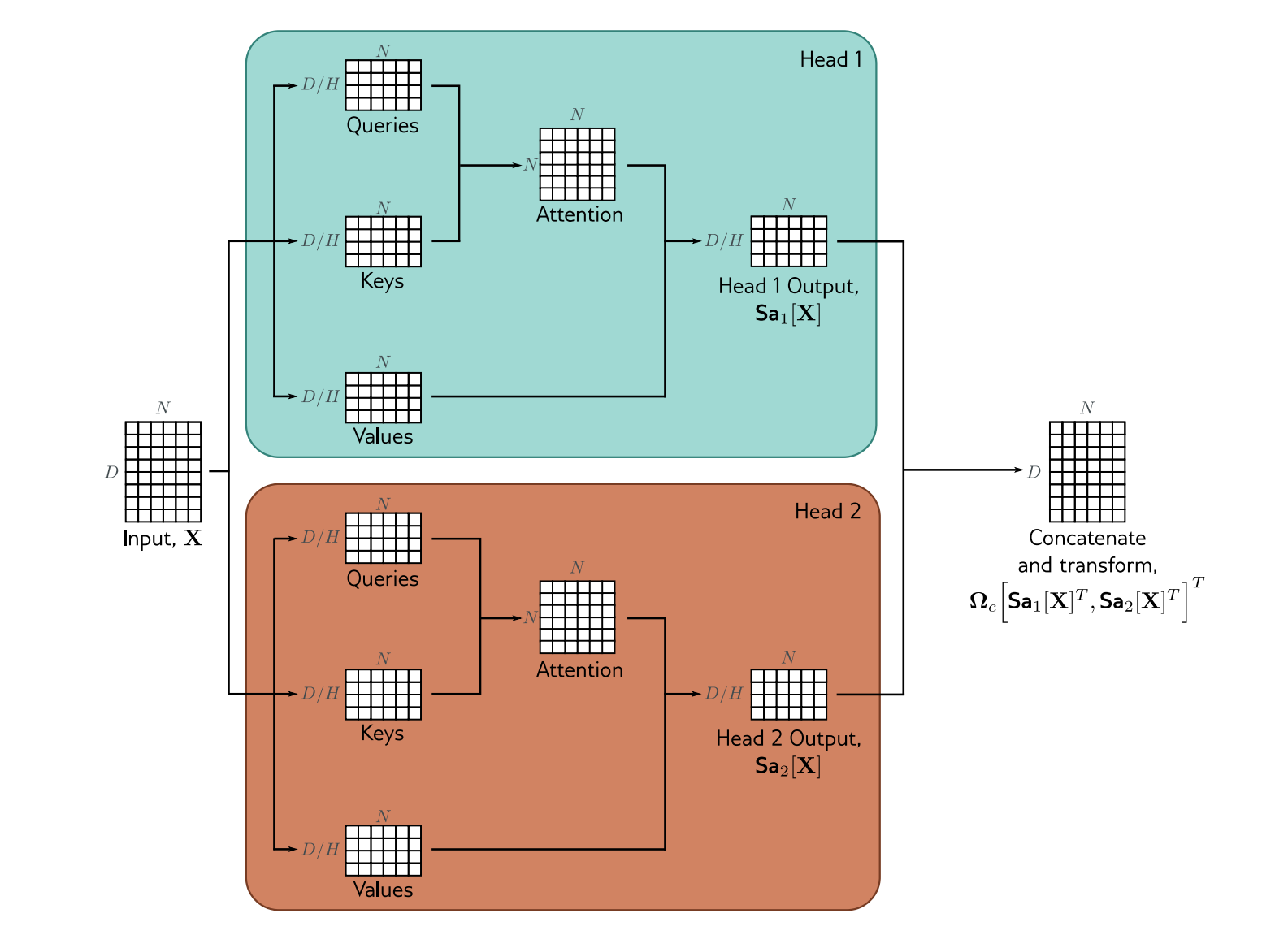
上图展现了一个2-head的attention过程,把d*n拆成了两个(d/2)*n的矩阵,分别计算attention,最后把结果拼接起来,得到d*n的矩阵.
为什么多头?
- 多头注意力让模型能在不同的“注意力子空间”中,同时关注序列里的不同关系模式。(answered by GPT)
- 多头可以预防不好的initialization,增强模型鲁棒性(answered by Prince)
MHA(Multi-Head Attention):
每个 head 都有独立的 Q/K/V → 功能强、计算贵
MQA(Multi-Query Attention):
每个 head 只有 Q 不同,但 共享一份 K 和一份 V → 大幅降低显存和推理成本,是现代大模型主流。
KV-cache
在生成任务中,比如 GPT 这种 decoder架构,每次生成一个 token,都需要计算前面所有 token 的 attention,这样计算量会随着生成长度线性增加,导致推理速度变慢。使用一个cache存放已经计算过的K和V可以大大减少计算量和memory。
Q: 为什么 Query 不缓存?
A: 因为 Q(Query)只用在“当前 token”上,所以每次推理都需要新的 Q。缓存没有意义。
full fine-tunning
fine_tunning就是在预训练模型的基础上,针对具体任务进行微调
而full fine-tunning就是对模型所有参数都进行微调,灵活性高但计算成本巨大.
Parameter Efficient Fine-Tuning (PEFT)
接下来介绍几个只对部分参数进行微调的方法
Soft prompt
我们平常输入的prompt叫hard prompt. 这一部分会被tokenizer切割成很多token,然后经过word embedding操作变成 (H*D 的矩阵)
而soft prompt则是一串embedding的向量, (G*D 的矩阵). 我们将其输入到模型里,冻结模型的其他所有参数,只通过梯度反向传播更新这个向量。
在学习之后,我们就得到了这样一串学好的soft prompt 。
然后在用户使用时,用户会输入一个hard prompt, 我们将hard prompt和训练好的soft prompt连接(concatenate),把这个向量作为input: ( (H+G)*D 的矩阵)
相当于输入序列长度变大了(H->H+G),而每个token的维度没变 ), 这样可以让模型对特定任务表现更好。
soft prompt的好处是省显存,只需要更新soft prompt的向量就行了,参数量G*D, 如果像传统方法一样微调所有参数的话,参数量一般是>=7B,非常需要算力。
soft-prefix
类似soft prompt, 但不是在input的前面加一串向量, 而是加在每一层的attention的K,V里. 但Q不变.
soft prompt是多了G个token,因此Q,K,V的序列也都多了G列. 而soft prefix则可以看作多了G个隐藏文本,单个token查询不仅要查输入文本token的k,还有soft-prefix加的隐藏文本的k. 但当前文本长度是不变的,因此Q没有变化.
LoRA
Low-Rank Adaptation of Large Language Models.
在模型的某些权重矩阵W上,添加两个低秩矩阵A和B,使得微调时只更新A和B,而冻结W。
在 LoRA 中,权重更新矩阵表示为:
其中:
- r是低秩(rank),通常远小于
1. 初始化原则
矩阵 B 初始化为较小的随机值
- 目的是让 LoRA 初始输出接近 0,不影响原模型的输出
- 常用方法:
- 均匀分布: 其中 - 正态分布:
矩阵 A 初始化为零
- 这样
- 保证初始模型输出几乎不受 LoRA 影响
- 训练时 A 会逐渐学习如何调整权重
2. 为什么这样初始化
初始 LoRA 输出很小,模型性能不会突然变化; 训练过程中 LoRA 会逐步调整权重,避免梯度爆炸; 可以直接加载预训练模型,不破坏原模型知识
Adaptor
在模型中插入小型瓶颈网络,只训练这些模块,实现高效微调
在 Transformer 中,一般插在:
1️⃣ Attention 后
2️⃣ FeedForward 后
结构类似:
[Attention]
↓
[Adaptor] ← 插这里
↓
[FFN]
↓
[Adaptor] ← 也可以插这里
BERT
encoder结构,学习input的表征(representation)
BERT有SEP token,用于分隔句子。有CLS token,用于分类任务。采用bidirectional attention,即每个token的注意力都考虑到了它前面和后面的所有token。而GPT只采用了unidirectional attention,即每个token只考虑到了它前面的token。
BERT 训练采用 Masked Language Modeling (MLM):随机遮住词,要求模型利用左右上下文预测. 这是unsupervised training, 不需要人工贴标签,可以用巨量语料学习语言规律, 从而得到一个强大的语言模型.
复杂度
传统softmax based attention 的时间复杂度是 , n是序列长度. 计算量主要来自于 . 每个 token 都要和其他 n 个 token 计算 attention score, 就是拿一个certain token的Q去和序列里所有的token的K做点积(dot product), Q,K是d维的,那么点积这一步就是O(d)的复杂度, 和n个token的K做点积,因此计算certain token的attention score的复杂度是 . 总共有 n 个 token, 那么就是 了.